LLM強化学習の崩壊を防ぐ新手法を開発
大規模言語モデルの強化学習訓練で生じる「エントロピー崩壊」を抑制する手法「STARE」が発表された。推論精度が最大8ポイント向上し、AIモデルの実用化コスト削減に直結する成果である。
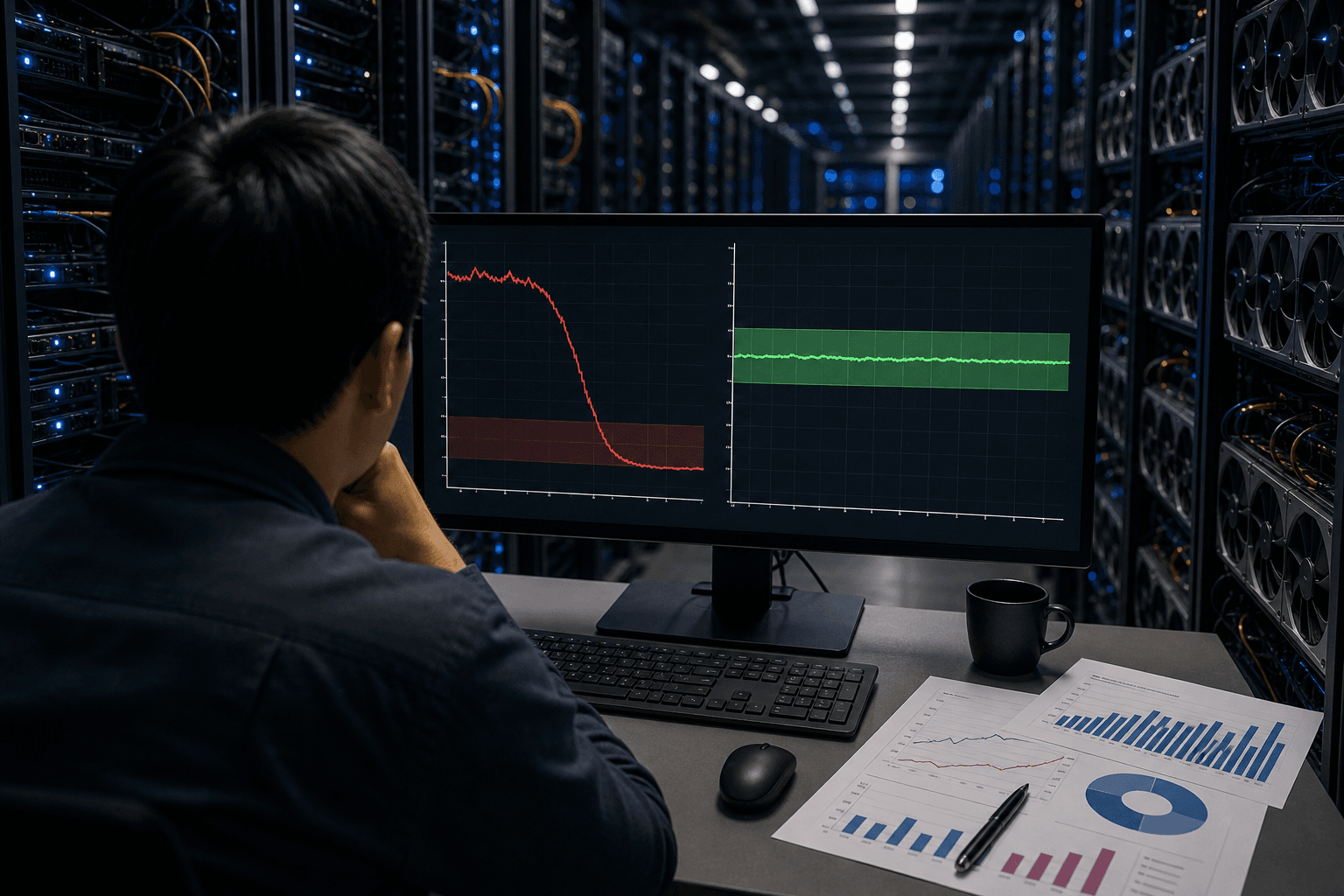
マイクロソフト・リサーチの研究チームは、大規模言語モデル(LLM)の後訓練に用いられる強化学習アルゴリズムが抱える根本的な課題を解決する手法「STARE」を発表した。論文はarXivで公開されており、コードも公開済みである。
強化学習を用いたLLMの訓練では、モデルが特定の回答パターンに過度に収束し、多様な推論を失う「エントロピー崩壊」が深刻な問題となっている。この現象が起きると、モデルは新しい問題に対する探索能力を失い、精度が頭打ちになる。既存の主要アルゴリズムであるGRPOやDAPOはこの問題を完全には解消できていなかった。
STAREはトークン単位でのアドバンテージ再重み付けという独自のアプローチを採用する。モデルが予測しにくい「高サプライザル」トークンに着目し、それらが学習に与える影響を選択的に調整することで、数千ステップに及ぶ長期訓練でもエントロピーを安定した範囲内に維持する。1.5億から320億パラメータまでの複数モデル規模で検証され、数学的推論ベンチマークのAIME24およびAIME25において、比較手法を4〜8ポイント上回る精度を達成した。
ビジネスへの影響は複数の領域に及ぶ。まず金融機関のリスク管理部門では、契約書審査や法規制への適合確認に生成AIを活用する動きが加速しているが、モデルの推論一貫性の低下が誤判断リスクを高めるとして導入を躊躇する事例が多い。STAREによって訓練安定性が向上すれば、モデルの信頼性指標(エラー率・ハルシネーション発生率)の改善が期待でき、審査自動化率というKPIを引き上げる根拠となる。
製薬・素材分野の研究開発部門においても恩恵は大きい。化合物探索や実験計画の立案にLLMを用いる際、モデルが多様な仮説を生成し続ける能力は研究の質に直結する。エントロピー崩壊は仮説の多様性を損なうため、STAREのような安定化技術は研究サイクルの短縮というKPIに貢献しうる。
さらに、自社LLMの開発・ファインチューニングに取り組む企業のAI基盤チームにとっては、計算コストの観点が重要である。エントロピー崩壊が生じると再訓練が必要になり、GPU稼働時間と人件費が無駄になる。STAREは訓練の途中崩壊を防ぐことで、訓練コスト全体を削減し、モデルリリースまでのリードタイムを短縮する効果が見込まれる。クラウドコンピューティングのコスト削減率は重要なKPIであり、訓練の安定化はその直接的な改善手段となる。
複数ターンにわたるツール使用タスクでの検証結果は、カスタマーサポートや社内ヘルプデスクの自動化に向けたエージェント型AIの品質向上にも示唆を与える。長い会話を通じて一貫した推論を維持する能力は、顧客満足度スコアや一次解決率といったKPIに直結するからである。
コードはGitHub上で公開されており、既存のGRPOベースの訓練パイプラインへの統合が比較的容易とされる。自社でLLMを訓練する企業はすぐに検証に着手できる環境にある。AI投資の費用対効果を厳しく問われるなか、訓練安定性の確保は単なる技術的改善にとどまらず、AIプロジェクトの事業化判断を左右する要素となりつつある。
関連トピック
同セクションの記事
AI多エージェントが平易スペイン語文書を自動生成
スペイン語の「わかりやすい文章(Easy-to-Read)」を自動生成するAIシステムの研究成果が発表された。多エージェント制御により情報の正確性と読みやすさを両立し、法務・医療・金融など複雑な文書を扱う業界に広範な活用可能性をもたらす。

AI情報源の信頼性を自動評価、新データベースが登場
英カーディフ大学らの研究チームが、メディア情報源の信頼性をAIで自動評価するための公開知識ベース「MEDIAREF」を発表した。フェイクニュース対策やコンプライアンス管理のコスト削減に直結する成果として注目される。

ViT内部構造の解明、AI開発効率化へ
インド工科大学らの研究チームがビジョントランスフォーマーの学習過程における表現幾何学を体系的に解析するフレームワーク「TGO-II」を発表した。AIモデルのブラックボックス問題に切り込み、開発コスト削減と信頼性向上に寄与する可能性がある。
